![[レポート] DynamoDB の詳細な設計が学べるビルダーズセッション「Applied data modeling with Amazon DynamoDB [REPEAT]」 #DAT401-R #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート] DynamoDB の詳細な設計が学べるビルダーズセッション「Applied data modeling with Amazon DynamoDB [REPEAT]」 #DAT401-R #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
コーヒーが好きな emi です。
AWS re:Invent 2024 で Builders' session 「Applied data modeling with Amazon DynamoDB [REPEAT](Amazon DynamoDB を使用した応用データモデリング)」に参加しました。
[REPEAT] がついているのは re:Invent 期間中何回か開催されるセッションです。
このビルダーズセッションでは、DynamoDB を使用したデータモデリングに焦点が当てられました。
ディスカッションでは、パーティショニングとソートキー、追加のアクセスパターン用のグローバルセカンダリインデックス(GSI)について学び、e コマースストアのユースケースを例にワークを行いました。
概要
タイトル:DAT401-R | Applied data modeling with Amazon DynamoDB [REPEAT]
このビルダー向けセッションでは、新しいビジネスアイデアをAmazon DynamoDBの完全な機能を持つデータモデルに変換する方法を学びます。ビジネス要件をアクセスパターンに、アクセスパターンを完全に最適化されたスキーマ設計に変換する方法を学びます。参加するには、ノートパソコンをご持参ください。
スピーカー
Sean Shriver(Sr. DynamoDB Solutions Architect, AWS)
Robert McCauley(DynamoDB Solutions Architect, AWS)
Arjan Schaaf(Senior DynamoDB Specialist Solutions Architect, Amazon Web Services)
Anamika Kesharwani(Partner Solutions Architect, Amazon Web Services)
Michael Raney(Principal Specialist Solution Architect, Amazon)
Tuesday, December 3
5:30 PM - 6:30 PM PST
Wynn | Convention Promenade | Latour 7
Session types: Builders' session
Topic: Databases
Level: 400 – Expert
Role: Developer / Engineer, IT Professional / Technical Manager, Solution / Systems Architect
Services: Amazon DynamoDB
レポート
ビルダーズセッションは、ワークショップ形式で課題を進めつつ、講師と参加者が議論を交わしながら進める少人数のセッションです。人数は 10 名ほどだったと思います。
他のセッションと比べると小さな部屋でこじんまりとしていました。

最初に DynamoDB の特徴やアーキテクチャについて解説があります。

Example Corp(架空の企業)の新しいプロジェクトに取り組んでいると仮定してワークを始めます。
データモデルを構築するには、以下の情報が必要です。
- 保存するエンティティのリスト
- アプリケーションで扱うデータの「種類」や「モデル」など。たとえば、「ユーザー」 「注文」 「製品」など
- アクセスパターン(読み取り/書き込み)のリスト
- 各エンティティのおおよそのサイズ、カーディナリティ、スループット

Example Corp のエンティティの関係はこのようになっています。
e コマースストアを構築するストーリーで、顧客は気に入った商品を見つけたらカートに追加し、カートの中身を注文することができます。
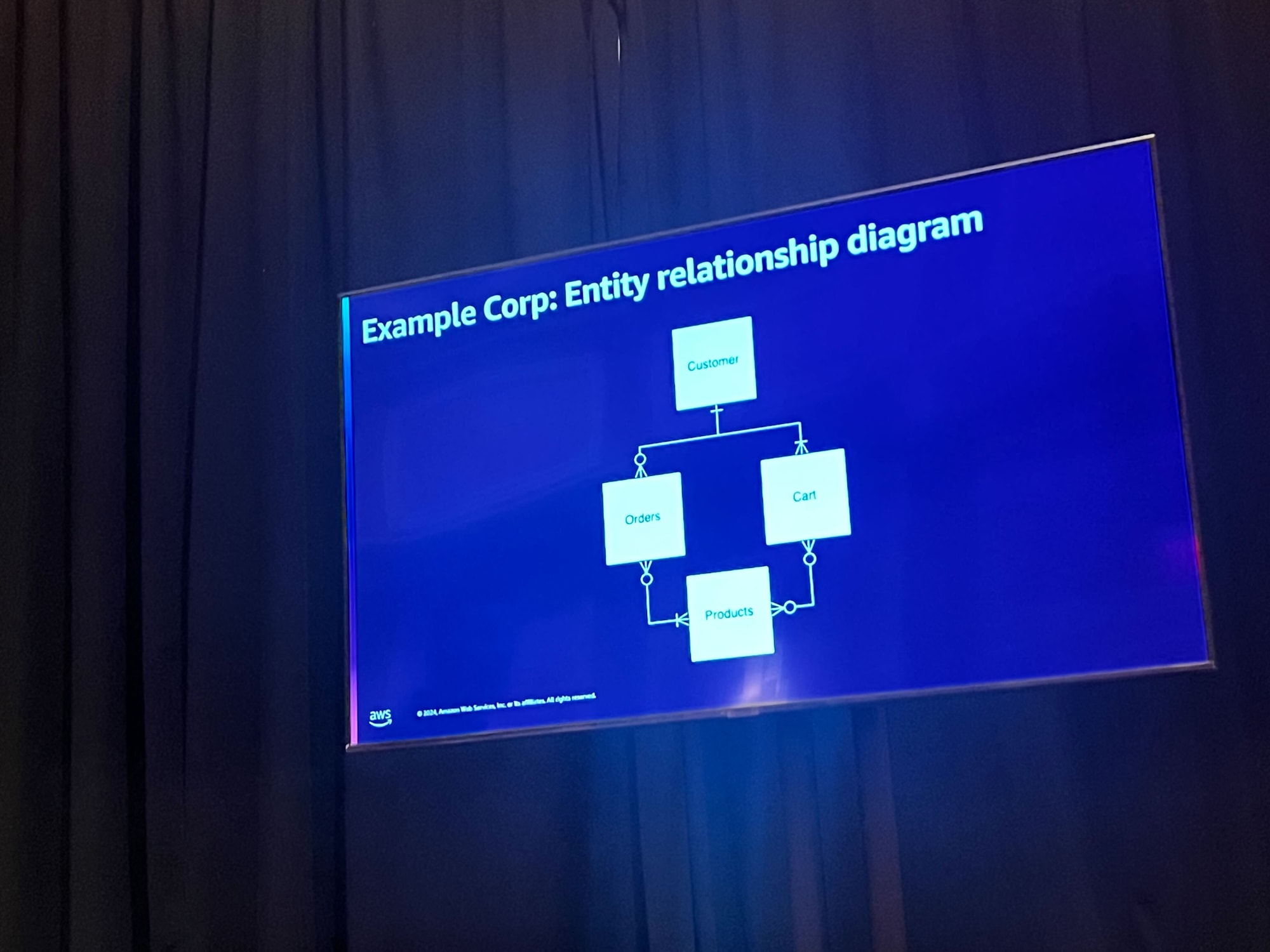
Example Corp のアクセスパターンは以下の想定です。
- 顧客がショッピングカートに商品を追加する
- 顧客が後で使用するために商品をカートに保存する
- 顧客がカート内のアクティブな商品に対して注文を作成する
- 顧客が自身の注文を確認する
- Example Corpが商品の在庫を更新する

モジュール 0: はじめに (Introduction)
Eコマースプラットフォームのデータベース設計を始めます。
各エンティティについて、カーディナリティ、平均データサイズ、書き込み・読み取り頻度を書き出します。
| Entity(エンティティ) | Cardinality(カーディナリティ) | Average size (KB)(平均サイズ:KB) | Write frequency(書き込み頻度) | Read frequency(読み取り頻度) |
|---|---|---|---|---|
| Customers(顧客) | High(顧客データが多い) | 2 | Medium | Medium |
| Products(商品) | Medium | 10 | Low | High |
| Shopping cart(ショッピングカート) | High | 1 | Medium | Low |
| Orders(注文) | High | 5 | Low | Medium |
Partition Key の選択
エンティティの特徴を書き出したら、DynamoDB テーブルのパーティションにわたるデータの分散を決定するために、パーティションキー(PK)を決定します。ソートキー(SK)を持たないテーブルでは、PK は各項目に対して一意である必要がありますが、このワークショップでは各項目に SK を割り当てるので、データ分散に使用できる各エンティティの PK の選択に焦点を当てます。
ワークではいくつかの質問に答えながらパーテイションキーをどれにするか考えていきました。
- Products
- Productsを所有する人物像は誰ですか? → Example Corp
- 同時に複数の製品を照会するアクセスパターンはありますか? → No
- 各製品がユニークである場合、PKは何になりますか? → ProductID
- Customers
- Customersを所有する人物像は誰ですか? → Customers 自身
- 同時に複数の顧客を照会するアクセスパターンはありますか? → No
:
こんな感じで所有者を考え、アクセスパターンを考えると、PK が決定できます。
ポイントは、関連するデータを一緒にクエリするために、同じパーティションキーを使用すると、クエリ効率が向上する点です。
DynamoDB では、パーティションキー(PK)はデータを物理的に分散するために使用されます。同じPKを持つアイテムは、同じパーティションに格納されます。これにより、関連データを効率的にクエリすることが可能です。
ソートキー(SK)は、PK 内でのアイテムの順序や識別を補助するために使用されます。
- 顧客(Customers)、ショッピングカート(Shopping Cart)、注文(Orders)といった関連データをクエリする場合、同じ CustomerID を PK として使用することで、1 回のクエリで関連データを取得できます。
- 同じ PK を使用することで、1 人の顧客に関連するすべてのデータを同じパーテイションに格納できます。
- 例えば「Customer#12345」のすべてのデータを取得したい場合、クエリ条件
PK = "Customer#12345"を指定すれば、顧客情報、カート内容、注文履歴を一度に取得できます。
- 商品データ(Products)は CustomerID に基づくクエリを必要としません。商品ID(ProductID)で個別にアクセスされるケースが多いです。
- 商品データを同じテーブルに格納すると、関連のない商品データも含めてスキャンされる可能性があり、クエリ効率が低下します。
- このため Product だけは別のテーブルにします。
Sort Key の選択
このケースにおけるパーティションキー(PK)は、関連するアイテムを整理して一緒に格納するためのものです。アイテムごとの一意性を保証するために、追加でソートキー(SK)を決定する必要があります。
PK のときと同様に、いくつかの質問に答えながら SK を考えていきます。
- Products
- ProductID の PK は、Product の一意性を保証するのに十分ですか?→ Yes. products テーブルにソートキーを含める必要はない
- Customers
- CustomerID の PK は、Customer の一意性を保証するのに十分ですか?→ Yes. 一般的には顧客に一意の識別子があるのが普通
- 追加の一意性やソートは必要ないので、当社の SK 値は何にできますか?→ 固定で静的な値を選択できる。 SK は空にできない ので、1 文字でも十分(例:「root」や「meta」、「!」など)。
- Shopping Cart
- CustomerID の PK はショッピングカートの一意性を保証するのに十分ですか?→ No. ショッピングカートには多くの ProductID が保存される
- 顧客はショッピングカートに何を入れる必要があるでしょうか?→ 製品
- 当社のアクセスパターンでは、ショッピングカート内の製品をソートまたはフィルタリングする必要がありますか?→ Yes. 製品のステータスによってデータをソートしたい場合もある
:
最終的にプライマリキーは以下のようになりました。
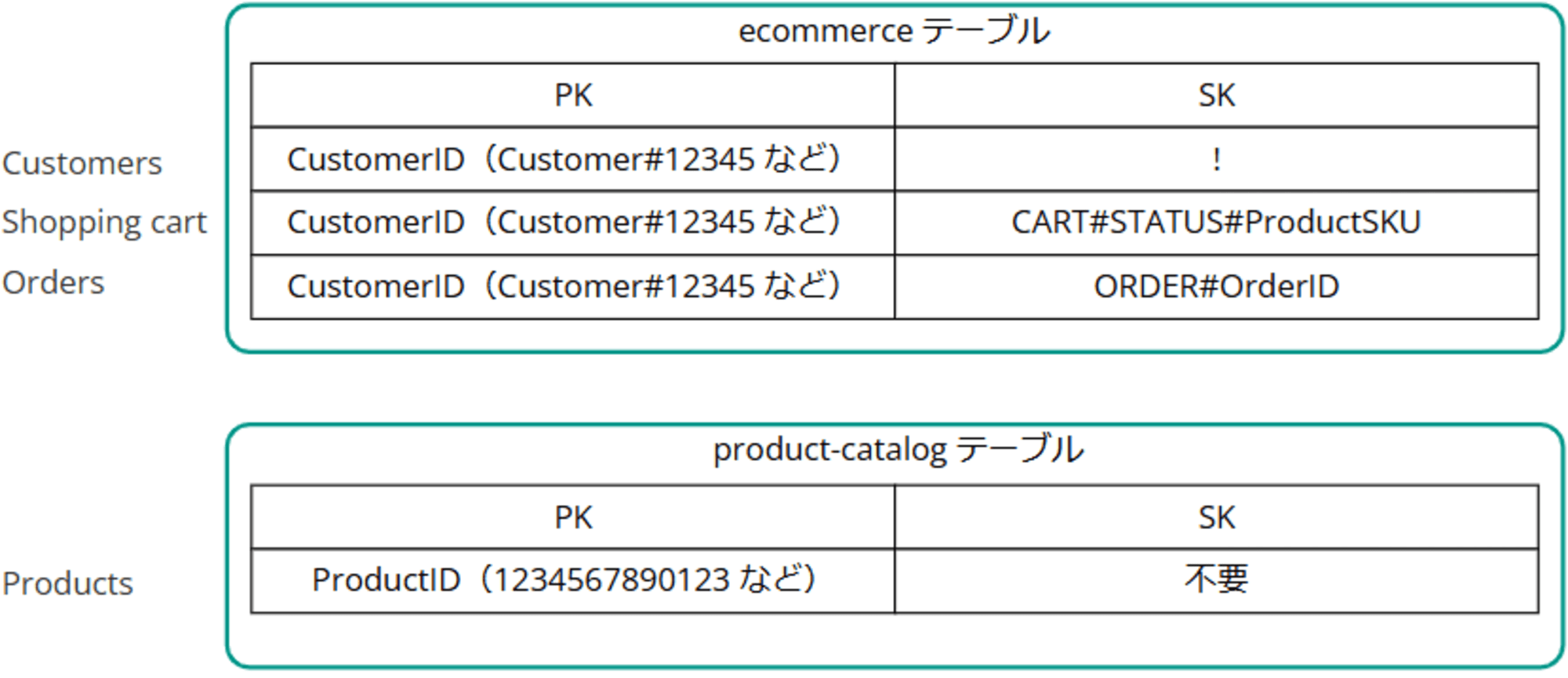
Shopping Cart の SK は STATUS に ACTIVE や SAVED が入ります。#ProductSKU には Apples や Bananas など製品が入ります。これは「複合ソートキー(Composite Sort Key)」と呼ばれるものです。
効率的かつスケーラブルなデータアクセスが実現できる設計になりました。
ワークで準備された環境に DynamoDB テーブルを構築し、データを取得してみます。
[cloudshell-user@ip-10-144-123-23 ~]$ aws dynamodb get-item \
> --table-name ecommerce \
> --region us-west-2 \
> --key '{"PK": {"S": "Customer#0001"}, "SK": {"S": "!"}}'
{
"Item": {
"SK": {
"S": "!"
},
"PK": {
"S": "Customer#0001"
},
"FirstName": {
"S": "Clinton"
},
"LastName": {
"S": "Barrett"
}
}
}
[cloudshell-user@ip-10-144-123-23 ~]$
モジュール 0 で結構お腹いっぱいです!
モジュール 1: 読み取りの最適化 (Optimize Reads)
まず CustomerID Customer#0001 に紐づくすべての注文(Orders)を取得するクエリを実行します。
[cloudshell-user@ip-10-144-123-23 ~]$ aws dynamodb query \
> --table-name ecommerce \
> --region us-west-2 \
> --key-condition-expression "PK = :PK and begins_with(SK, :SK)" \
> --expression-attribute-values '{":PK": {"S": "Customer#0001"}, ":SK": {"S": "Order"}}' \
> --return-consumed-capacity TOTAL \
> --query "{Count: Count, ConsumedCapacity: ConsumedCapacity}"
{
"Count": 416,
"ConsumedCapacity": {
"TableName": "ecommerce",
"CapacityUnits": 35.5
}
}
[cloudshell-user@ip-10-144-123-23 ~]$
416 件の注文が返され、35.3 RCUを消費しました。416 件の注文の総データサイズは約 284KB と推定できます。(DynamoDB の RCU の結果整合性の計算 35.5 * 4KB / 0.5)。
クエリは現在の注文データサイズに比例してコストが増加するため、データ量が増えると効率が低下する可能性があります。
- 特定の期間の注文を取得するために
FilterExpressionを使用することはできるが、RCU の消費は減らせない(ネットワーク帯域幅の節約のみ) - 新しいソートキー構造の検討
- ソートキーに
OrderDateを含める複合キーを使う(例:OrderDate#OrderID) - 特定の期間をクエリする際に、
OrderDateで範囲クエリが可能になる
- ソートキーに
- GSI(グローバルセカンダリインデックス) の使用
- GSI を作成し、
CustomerIDを PK、OrderDateを SK として設定。
- GSI を作成し、
[cloudshell-user@ip-10-144-123-23 ~]$ TODAY=$(date +%F)
[cloudshell-user@ip-10-144-123-23 ~]$ FOURTEEN_DAYS_AGO=$(date -d "-14 days" +%F)
[cloudshell-user@ip-10-144-123-23 ~]$ aws dynamodb query \
> --table-name ecommerce \
> --index-name OrderIndex \
> --region us-west-2 \
> --key-condition-expression "PK = :PK AND OrderDate BETWEEN :startDate AND :endDate" \
> --expression-attribute-values "{\"":PK\"": {\"S\": \"Customer#0001\"}, \":startDate\": {\"S\": \"$FOURTEEN_DAYS_AGO\"}, \":endDate\": {\"S\": \"$TODAY\"}}" \
> --return-consumed-capacity TOTAL \
> --query "{Items: Items[*].OrderDate.S, Count: Count, ConsumedCapacity: ConsumedCapacity}"
{
"Items": [
"2024-11-20T06:34:16.220707",
"2024-11-20T19:37:49.145883",
"2024-11-24T18:21:34.994863",
"2024-11-25T15:30:04.902401",
"2024-11-25T22:52:23.229839",
"2024-11-29T05:05:50.675135",
"2024-11-29T23:46:32.155850",
"2024-11-30T16:10:53.924460"
],
"Count": 8,
"ConsumedCapacity": {
"TableName": "ecommerce",
"CapacityUnits": 0.5
}
}
[cloudshell-user@ip-10-144-123-23 ~]$
GSI を作成し SK として OrderDate を設定したことで特定日付範囲のデータのみクエリできるようになり、クエリコストは大幅に削減され、0.5 RCUでデータを取得可能になりました。
モジュール 2: 更新の最適化 (Optimize Updates)
次は product-catalog テーブルについて考えます。
製品が購入されると、製品カタログの在庫数は減らさなければなりません。倉庫に商品の在庫が補充された場合は、商品の再入荷を反映して在庫数を更新する必要があります。
product-catalog テーブルは以下のような構造になっているとします。
| Attribute | Data Type | Description | Example |
|---|---|---|---|
| PK | String | Unique Product ID/GTIN | 6296884934275 |
| name | String | Name of the Product | FitForge FlexBand |
| brand_name | String | Name of the Brand | FitForge |
| category | String | Category of the Brand | fitness equipment |
| description | String | Large blob of text about the product | Introducing the FitForge FlexBand...specific muscle groups. |
| inventory | Number | Count of products available | 82 |
| others | various | Other non-key attributes | last_modified_time, gtin14, brand_shard [we will discuss this attribute in module 4] |
- DynamoDB では、1 回の更新操作はアイテム全体のサイズに基づいて書き込みユニット (WCU) を消費
- 商品の在庫数(
inventory)だけを更新しても、アイテム全体(商品の説明文や他の属性)のサイズが影響
アイテムのアップデートに関して、垂直パーティショニング(Vertical Partitioning) を利用すると、効率的にアップデートできます。
- 垂直パーティショニング(Vertical Partitioning)
- データを次の2つのカテゴリに分割
- 静的データ (Static Data): 更新されない大きな属性(商品説明など)
- 頻繁に変更されるデータ (Warm Data): 在庫数などの小さな属性
- データを次の2つのカテゴリに分割
こんな感じで、ソートキーを分割します。
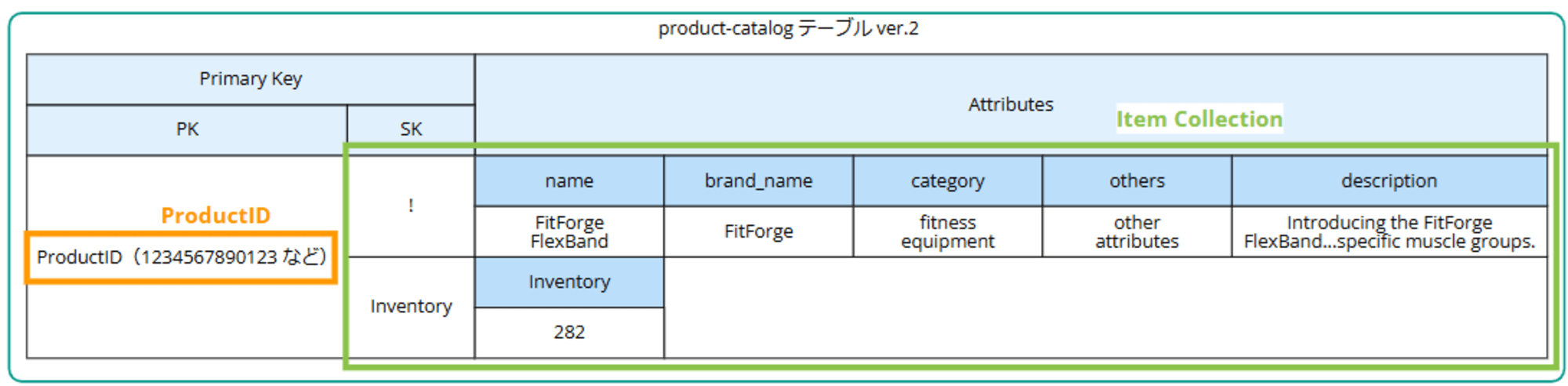
product-catalog-v2 テーブルを作成し直しデータを再度挿入します。
テーブルの再作成時は従量課金モードを指定していました。
[cloudshell-user@ip-10-144-123-23 ~]$ aws dynamodb create-table --table-name product-catalog-v2 \
> --attribute-definitions AttributeName=PK,AttributeType=S AttributeName=SK,AttributeType=S \
> --key-schema AttributeName=PK,KeyType=HASH AttributeName=SK,KeyType=RANGE \
> --billing-mode PAY_PER_REQUEST \
> --region us-west-2 \
> --query '{TableName: TableDescription.TableName, TableStatus: TableDescription.TableStatus}'
{
"TableName": "product-catalog-v2",
"TableStatus": "CREATING"
}
[cloudshell-user@ip-10-144-123-23 ~]$
商品のアップデートを実行します。
[cloudshell-user@ip-10-144-123-23 ~]$ aws dynamodb update-item \
> --table-name product-catalog-v2 \
> --region us-west-2 \
> --key '{"PK": {"S": "6296884934275"}, "SK": {"S": "inventory"}}' \
> --update-expression "SET inventory = inventory + :incr" \
> --expression-attribute-values '{":incr":{"N":"200"}}' \
> --return-consumed-capacity TOTAL
{
"ConsumedCapacity": {
"TableName": "product-catalog-v2",
"CapacityUnits": 1.0
}
}
[cloudshell-user@ip-10-144-123-23 ~]$
- PK
"6296884934275"と SK"inventory"の商品について、在庫数を 200 増加 - 使用された WCU はわずか 1.0 で、節約できている
- 大量の属性を持つエンティティで、一部のデータが頻繁に更新されるユースケースで効果的
モジュール 3: 必要なデータの効率的検索 (Needle in a haystack:針の山から一本の針を探す)
一部の属性(1 つ星評価など)がまばらなデータを検索すると、大量のスキャンが発生し非効率です。
- クエリ: 指定された PK と SK の条件に基づいてデータを取得
- スキャン: テーブル全体または特定のパーティションを走査してすべてのデータをチェック
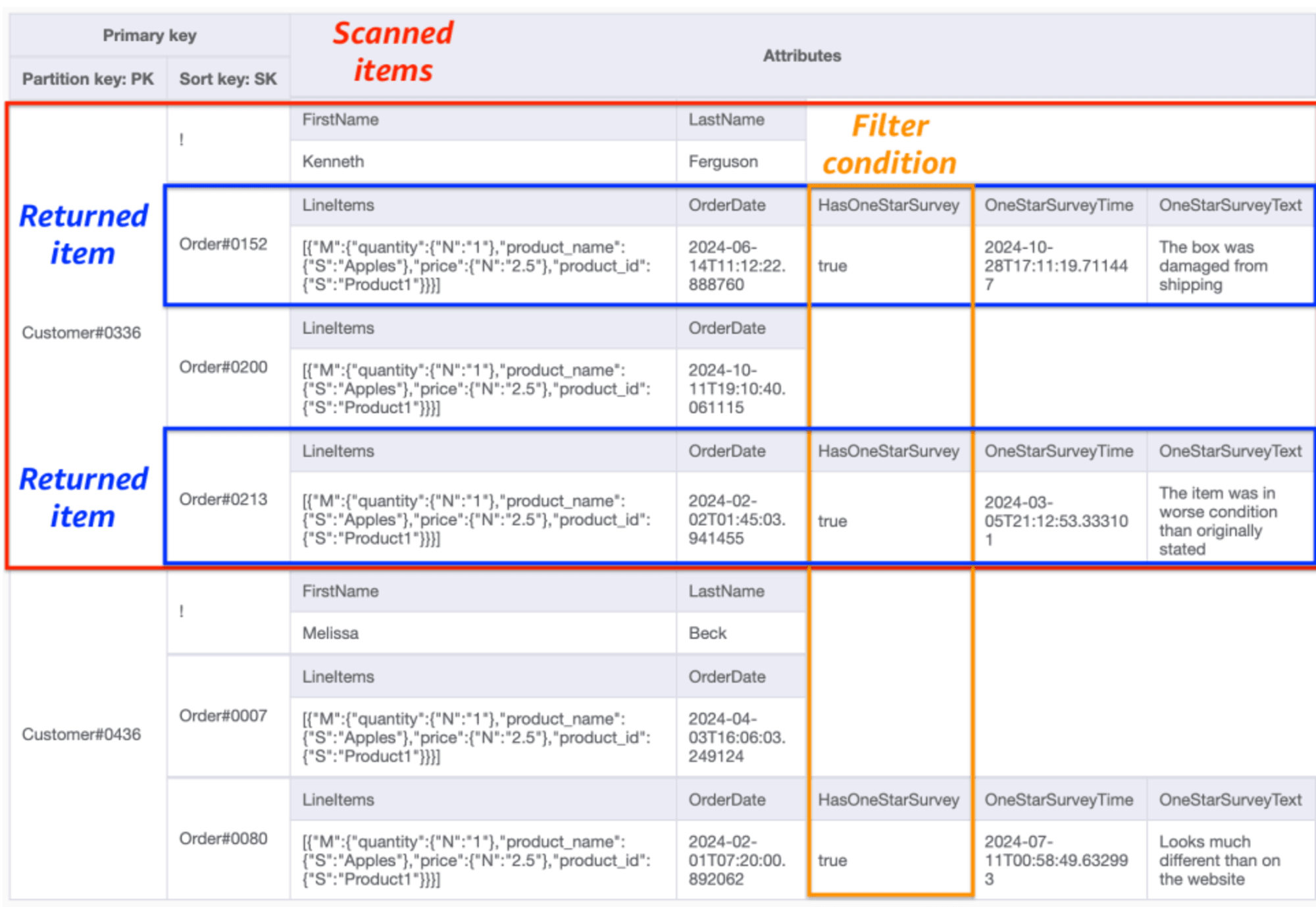
フィルタ条件はスキャン後に適用されるため、スキャン数(赤枠)は減らせません。
[cloudshell-user@ip-10-144-123-23 ~]$ aws dynamodb query \
> --select "COUNT" \
> --table-name ecommerce \
> --return-consumed-capacity TOTAL \
> --key-condition-expression "PK = :pkValue" \
> --filter-expression "HasOneStarSurvey = :hasOneStarSurveyTrue" \
> --expression-attribute-values '{":pkValue":{"S":"Customer#0001"}, ":hasOneStarSurveyTrue":{"S":"true"}}'
{
"Count": 24,
"ScannedCount": 417,
"ConsumedCapacity": {
"TableName": "ecommerce",
"CapacityUnits": 35.5
}
}
[cloudshell-user@ip-10-144-123-23 ~]$
結果は 24 項目ですが、417 項目をスキャンし、35.5 RCU を消費しました。ScannedCount と Count の比率が偏っている場合、探しているデータは「Sparse(疎)」であると言います。Sparse data(スパースデータ、疎データ)とは、大規模なデータセットに薄く、またはまばらに分布しているデータのことです。
- sparse index(スパースインデックス) の導入
- GSI を活用し、特定属性が存在するアイテムだけをインデックス化
HasOneStarSurveyIndexという GSI を作成し、1 つ星評価の注文を効率的に検索
以下のようにスパースインデックスを追加するコマンドが紹介されていましたが、ワークの環境ではスパースインデックスは既に作成済みでした。HasOneStarSurveyIndex という GSI をスパースインデックスとして設定しています。HasOneStarSurveyIndex は HasOneStarSurvey 属性が true(1 つ星レビューが存在する)のみを対象としたインデックスです。
aws dynamodb update-table \
--table-name ecommerce \
--attribute-definitions \
AttributeName=PK,AttributeType=S \
AttributeName=HasOneStarSurvey,AttributeType=S \
--global-secondary-index-updates \
'[
{
"Create": {
"IndexName": "HasOneStarSurveyIndex",
"KeySchema": [
{"AttributeName": "PK", "KeyType": "HASH"},
{"AttributeName": "HasOneStarSurvey", "KeyType": "RANGE"}
],
"Projection": {
"ProjectionType": "ALL"
}
}
}
]'
以下で結果を確認します。
[cloudshell-user@ip-10-144-123-23 ~]$ aws dynamodb query \
> --select "COUNT" \
> --table-name ecommerce \
> --index-name HasOneStarSurveyIndex \
> --return-consumed-capacity TOTAL \
> --key-condition-expression "PK = :pkValue" \
> --expression-attribute-values '{":pkValue":{"S":"Customer#0001"}}'
{
"Count": 24,
"ScannedCount": 24,
"ConsumedCapacity": {
"TableName": "ecommerce",
"CapacityUnits": 2.5
}
}
[cloudshell-user@ip-10-144-123-23 ~]$
スパースインデックスの ScannedCount と Count は、フィルタリングを行わなくても等しくなります。ScannedCount の数は 417 から 24 に減少し、RCU は 35.5 から 2.5 に減少しました。
しかし、このスパースインデックスだと、「過去 6 ヶ月間の 1 つ星評価」など、期間でクエリすることができません。そこで、OneStarSurveyByTimeIndex という GSI を追加し、レビューの日時でソートできるようにします。
aws dynamodb update-table \
--table-name ecommerce \
--attribute-definitions \
AttributeName=PK,AttributeType=S \
AttributeName=OneStarSurveyTime,AttributeType=S \
--global-secondary-index-updates \
'[
{
"Create": {
"IndexName": "OneStarSurveyByTimeIndex",
"KeySchema": [
{"AttributeName": "PK", "KeyType": "HASH"},
{"AttributeName": "OneStarSurveyTime", "KeyType": "RANGE"}
],
"Projection": {
"ProjectionType": "INCLUDE",
"NonKeyAttributes":["OneStarSurveyText", "SK"]
}
}
}
]'
クエリします。
[cloudshell-user@ip-10-144-123-23 ~]$ aws dynamodb query \
> --select "COUNT" \
> --table-name ecommerce \
> --index-name OneStarSurveyByTimeIndex \
> --return-consumed-capacity TOTAL \
> --key-condition-expression "PK = :pkValue AND OneStarSurveyTime >= :sixMonthsAgo" \
> --expression-attribute-values "{\":pkValue\":{\"S\":\"Customer#0001\"}, \":sixMonthsAgo\":{\"S\":\"${SIX_MOS_AGO}T00:00:00\"}}"
{
"Count": 2,
"ScannedCount": 2,
"ConsumedCapacity": {
"TableName": "ecommerce",
"CapacityUnits": 0.5
}
}
[cloudshell-user@ip-10-144-123-23 ~]$
ソートキーを使用して タイムスタンプ 属性に基づいてフィルタリングすることで、返されるアイテムの数がさらに減少し、ScannedCount は希望するアイテムの正確な数と一致するようになりました。さらに、OneStarSurveyText 属性と SK のみを射影(projection)することで、アイテムのサイズとスキャンに必要な容量が大幅に減少しました。
スパースインデックスを使用してコストを節約し、スパースデータのクエリのパフォーマンスを向上させることができます。
先日の DynamoDB の値下げについても触れられていました。
モジュール 4: 商品カタログの検索 (Searching the Product Catalog)
製品カタログ(product-catalog)から製品を検索する際、通常のクエリではテーブル全体をスキャンしてからフィルタリングされるため多くの RCU が消費されコストが高く効率が悪いです。
- 読み取りコストの計算例
- テーブル内の 50,000件 のアイテム(1 件あたり 2,200 バイト)をスキャンする場合
- 総データサイズ = 50,000 × 2,200 バイト = 110,000,000 バイト(110 MB)
- 読み取りコスト(Eventually Consistent)
- 110,000 KB ÷ 4KB ÷ 2 = 13,750 RCUs
- 読み取りコスト(Strongly Consistent)
- 110,000 KB ÷ 4KB = 27,500 RCUs
- テーブル内の 50,000件 のアイテム(1 件あたり 2,200 バイト)をスキャンする場合
- Scan の実行例
[cloudshell-user@ip-10-144-123-23 ~]$ aws dynamodb scan \
> --table-name product-catalog \
> --filter-expression "brand_name = :brand_name_val" \
> --expression-attribute-values '{":brand_name_val":{"S":"VitalVive"}}' \
> --select "COUNT" \
> --return-consumed-capacity "TOTAL"
{
"Count": 5,
"ScannedCount": 150,
"ConsumedCapacity": {
"TableName": "product-catalog",
"CapacityUnits": 25.0
}
}
[cloudshell-user@ip-10-144-123-23 ~]$
150 件もスキャンしているのに対し、実際にクエリ条件に一致したのは 5 件です。RCU も 25.0 消費していて効率が悪いです。
-
GSI と ライトシャーディング (Write Sharding)
- DynamoDB の GSI と ライトシャーディング を組み合わせて検索効率を最適化
-
ライトシャーディング
- パーティションキーにランダムなサフィックス(例:
Shard#1,Shard#2, ...)を追加して、データを複数のパーティションに分散させる方法 - DynamoDB が内部で自動的にデータを分散配置するため、パフォーマンスが向上
- パーティションキーにランダムなサフィックス(例:
-
GSI(brand-index)の設計
- GSI 名:
brand-index - パーティションキー (PK):
brand_shard(例:Shard#1,Shard#2) - ソートキー (SK):
brand_name(例:FitForge,VitalVive) - プロジェクション: 必要な属性をすべて含む
- GSI 名:
単一シャードクエリ
ブランド名が "F" で始まるアイテムを検索
[cloudshell-user@ip-10-144-123-23 ~]$ aws dynamodb query \
> --select "COUNT" \
> --table-name product-catalog \
> --index-name brand-index \
> --return-consumed-capacity TOTAL \
> --key-condition-expression "brand_shard = :pkValue and begins_with(brand_name, :skprefix)" \
> --expression-attribute-values '{":pkValue":{"S":"Shard#1"}, ":skprefix":{"S":"F"}}'
{
"Count": 3,
"ScannedCount": 3,
"ConsumedCapacity": {
"TableName": "product-catalog",
"CapacityUnits": 0.5
}
}
[cloudshell-user@ip-10-144-123-23 ~]$
スキャンされた件数もクエリ条件に一致する件数も 3 件であり、効率的にスキャンできています。しかし、単一シャードしかクエリしていないため、他のシャードにも F で始まるブランドのアイテムが存在する可能性があります。
並列シャードクエリ
複数のシャードを並列クエリしてパフォーマンスを向上させるための Bash スクリプトの例です。
[cloudshell-user@ip-10-144-123-23 ~]$ for i in {1..9}
> do
> aws dynamodb query \
> --select "COUNT" \
> --table-name product-catalog \
> --index-name brand-index \
> --return-consumed-capacity TOTAL \
> --key-condition-expression "brand_shard = :pkValue and begins_with(brand_name, :skprefix)" \
> --expression-attribute-values '{":pkValue":{"S":"Shard#'$i'"},":skprefix":{"S":"F"}}' \
> --query "Count"
> done
3
0
4
0
2
2
6
2
1
[cloudshell-user@ip-10-144-123-23 ~]$
このコマンドは product-catalog に対して、GSI brand-index を使用し、"F"で始まるブランド名 (brand_name) をすべてのシャード (Shard#1 ~ Shard#9) に対して検索するクエリをループ処理で実行しています。
ブランド名やカテゴリ、説明文など複数の属性を検索する場合、DynamoDB よりも OpenSearch Service のようなフルテキスト検索エンジンを検討するべきとのことです。
ラボには OpenSearch Service との Zero-ETL を使った検索の最適化パートもありましたが、私が実施できたのはここまででした。

おわりに
DynamoDB の設計に関する詳細な使い方を知れて有意義でした。パフォーマンスが出ない場合やコストがかかってしまっている場合に役立ちそうです。
ビルダーズセッションはワークショップ形式ですが、終始参加者の皆さんと講師の方が議論をしていてすごく盛り上がっていました。私はワークに集中するので精一杯かつ英語が難しくて聞き取れなかったのが残念です。
他のビルダーズセッションでは参加者が初めに自己紹介をする形式のものもあったそうで、場合によっては英語力が必要になることもあるようです。
また、PC を持ってきてください、と書いてあるセッションでは基本ワークがあるのですが、PC からコンセントまで遠い場合があるので長い充電ケーブルや延長コードがあるといいかもしれないです。私は充電コードの長さが足りなかったので意識的にコンセントの近くに座っていました。1 時間程度のセッションならモバイルバッテリーで問題ないと思いますが、私はセッションの合間でブログを書いたりするので常にコンセントを探していました。







